## Streamendous workshop [BDA](https://bda2025.iiitb.net/) - July 2025 `https://streamspan.univ-nantes.io/workshop/` Use space for next slide, left/right to navigate sections, up/down to navigate in a section, ESC to get an overview <!-- .element: class="specifications" --> ## Goals - Experiment with streaming data processing, especially window manipulation and aggregation ## Requirements - Code and documentation: [https://gitlab.univ-nantes.fr/streamspan/workshop](https://gitlab.univ-nantes.fr/streamspan/workshop) - Laptop with **Linux**, **MacOS** or **Windows with WSL**. - Python will be used for some experiments and infrastructure - We will be using [**Podman**](https://podman.io/) to run Apache Kafka. ## Architecture overview The workshop will launch in podman containers - a single Kafka server (no distribution involved here) - a Web UI to inspect the behaviour of the Kafka Server, accessible at [`http://localhost:8080`](http://localhost:8080) - a Ksqldb server to experiment with Ksql on the data --- ## Podman - `podman` is an open source tool for developing, managing, and running containers - It is an alternative to `docker` for running containers, compatible with it (you can even declare `podman` as an alias for `docker`) - Compared to `docker`, it is rootless (does not require any admin rights) and daemon-less (does not require any daemon running in the background) ## Podman-compose - `podman-compose` (the equivalent of `docker-compose`) is used to orchestrate multiple containers - it reads the specification for the containers from a `podman-compose.yml` or `docker-compose.yml` configuration file and runs corresponding `podman` commmands ## Installation Details in [`README.md`](https://gitlab.univ-nantes.fr/streamspan/workshop/-/blob/main/README.md) - Install podman from `https://podman.io/` - Install `podman-compose` from `https://github.com/containers/podman-compose` ## Check podman installation As a test you can run `podman run -ti alpine /bin/sh` - It downloads and runs a small linux VM using the Alpine lightweight image - It opens a live interactive shell in it - You can explore a bit (`ls /usr/bin` for instance to see what is present) before exiting the shell with `exit` to quit the VM --- ## Kafka **Apache Kafka** is an open-source distributed event streaming platform - Originally developed by LinkedIn, now part of the Apache Software Foundation - Designed for high-throughput, low-latency, and real-time data pipelines - Commonly used for stream processing, event sourcing, and log aggregation ## Kafka providers - Kafka has an open API specification with multiple implementations - The reference one is [Apache Kafka](https://kafka.apache.org/) - For convenience we will use the [Confluent Kafka](https://www.confluent.io/fr-fr/) version (see [differences](https://www.svix.com/resources/faq/kafka-vs-confluent/)) - [RedPanda](https://www.redpanda.com/) is a streaming server implementing the Kafka API in C++, with a focus on performance - [Samsa](https://github.com/CallistoLabsNYC/samsa) is an alternative written in Rust. ## Core Concepts - *Broker*: Kafka server that stores and serves data - *Producer*: Sends (publishes) data to Kafka - *Consumer*: Reads (subscribes) data from Kafka - *Topic*: Named stream of records - acts as a data category - *Partition*: A topic is split into partitions for scalability - *Cluster*: A group of brokers working together ## How Kafka Works - Producers publish messages to a specific topic - Each topic is divided into partitions - Kafka brokers store these messages - Consumers subscribe to topics and read messages sequentially - Kafka retains messages for a configurable retention period ## Kafka concepts 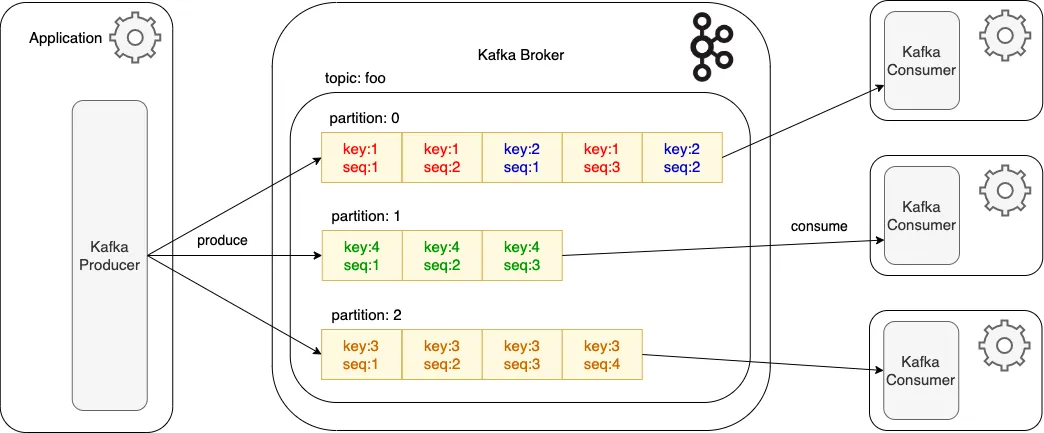 ## Partition definition From [ProducerRecord](https://kafka.apache.org/24/javadoc/org/apache/kafka/clients/producer/ProducerRecord.html): - If a valid partition number is specified, that partition will be used - If no partition is specified but a key is present a partition will be chosen using a hash of the key. - If neither key nor partition is present a partition will be assigned in a round-robin fashion. ## Partitions and consumers - each partition is consumed by exactly one consumer in the group - one consumer in the group can consume more than one partition - the number of consumer processes in a group must be less than number of partitions With these properties, Kafka is able to provide both *ordering guarantees* and *load balancing* over a pool of consumer processes. ## Key Features - *Durability*: Messages are written to disk and replicated across brokers - *Scalability*: Easily handles high volumes of data across multiple servers - *Fault Tolerance*: Automatically recovers from node failures - *Exactly-once Semantics*: Ensures no data is lost or duplicated (with proper setup) - *Real-Time Processing*: Integrates with tools like Kafka Streams, Flink, Spark ## Use Cases - Log Aggregation: Centralize logs from different services - Data Integration: Connect systems using Kafka Connect - Real-Time Analytics: Analyze streaming data in near real-time - Monitoring: Track metrics, events, and anomalies - Event-Driven Architectures: Microservices communication via Kafka events ## Stream processing in Kafka Different levels are possibles ([more complete list](https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=30747974#Ecosystem-StreamProcessing)): - write a consumer/processing/producer node - use the (java) [Kafka Streams API](https://kafka.apache.org/documentation/streams/) that provides facilities for local processing, aggregation, windowing... ([Faust-Streaming](https://faust-streaming.github.io/faust/) equivalent in python) - use the [Confluent Ksql](https://docs.confluent.io/platform/current/ksqldb/overview.html) server/syntax - use [Apache Flink](https://flink.apache.org/) (or Spark) --- ## Workshop In the context of the workshop, we will experiment with 2 approaches: - custom-built consumer/processing/producer node in python - Confluent Ksql syntax ## Workshop data model We are using a simplified [Call Detail Record](https://en.wikipedia.org/wiki/Call_detail_record) (CDR) model. ## Data generation The `cdr-generator` script generates a (finite) stream of calls, with a given **throughput** (number of calls per second) for a given **number of seconds**. Each call will have a duration respecting a lognormal distribution, with a specified **maximum call duration** `cdr-generator.py --help` for parameter help ## mono_signal.csv Each line represents a call. - *call_id*: unique id for the call - *start/end_timestamp*: in ms since 01/01/1970 - *start/end_timestring*: human-readable version for debug - *caller|callee*: identifier for caller/callee - *disposition*: call status (connected, busy, failed) ## tower.csv Each line represents a calling session segment that took place on the same antenna/tower. - *call_id*: call id (same as in `mono_signal.csv`) - *tower*: tower id - *start/end_timestamp*: timing information ## Workshop workflow - Using the `k` script as facade - Basic shell script that executes the appropriate podman/podman-compose commands. - Have a look at its content to see the actual commands. ## Workshop instructions Checkout the git repository: `git clone https://gitlab.univ-nantes.fr/streamspan/workshop` and follow the setup instructions in [`README.md`](https://gitlab.univ-nantes.fr/streamspan/workshop/-/blob/main/README.md) then the workshop instructions in [`NOTES.md`](https://gitlab.univ-nantes.fr/streamspan/workshop/-/blob/main/NOTES.md)